Ch10: 批次處理
- 「一個富有太多個人色彩的系統不太可能獲得成功。」- Donald Knuth
在本書的前兩部分,我們探討了許多關於請求和查詢以及相應的回應或結果的內容。現代資料系統經常採用這種處理方式:你發出請求,系統在一段時間後返回結果。這種線上系統的典型例子包括資料庫、快取、搜尋引擎和 Web 伺服器,這些系統通常由人類使用者觸發請求並等待響應,因此回應時間成為一個關鍵指標。 然而,構建系統的方式不僅限於此,還有其他方法具有其優勢。以下是三種不同型別的系統:
- 服務(線上系統):服務等待客戶請求,並儘快處理並返回回應。回應時間是其效能的主要衡量標準,可用性也非常重要。
- 批次處理系統(離線系統):這類系統處理大量輸入資料並生成輸出,通常需要較長時間,批次處理作業的主要效能衡量標準是吞吐量。
- 流式處理系統(近即時系統):介於線上系統和離線系統之間,流式處理系統在事件發生後不久進行處理,具有較低的延遲。
批次處理系統是構建可靠、可擴展和可維護應用程式的重要基礎,例如 2004 年的 MapReduce 演算法,大幅提升了處理規模。雖然 MapReduce 的重要性在下降,但它仍值得理解,因為它展示了批次處理的價值和實現方式。
批次處理的歷史可以追溯到早期的打孔卡製表機和 IBM 卡片分揀機,這些都是早期的批次處理形式。現代的批次處理系統,但首先,我們會從使用標準 Unix 工具進行資料處理開始。因為從 Unix 身上學到的思想與經驗可以應用到更大規模、異構的分散式資料系統當中。
使用 Unix 工具進行批次處理
access.log 是一個 Nginx 伺服器的日誌檔案,裡面記錄了每一個 HTTP 請求的詳細資訊。每一行都包含了一個時間戳記、用戶端的 IP 位址、請求方法、URL、HTTP 狀態碼、回應大小、來源網址和用戶端的 User-Agent 字串。例如:
216.58.210.78 - - [27/Feb/2015:17:55:11 +0000] "GET /css/typography.css HTTP/1.1"
200 3377 "http://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36"
簡易日誌分析
假設現在想要找出網站上最受歡迎的5個頁面是哪些,可以在 Unix shell 下這樣做:
cat /var/log/nginx/access.log | #1
awk '{print $7}' | #2
sort | #3
uniq -c | #4
sort -r -n | #5
head -n 5 #6
4189 /favicon.ico
3631 /2013/05/24/improving-security-of-ssh-private-keys.html
2124 /2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
1369 /
915 /css/typography.css
如果你對 Unix 命令鏈不熟,但這無損它們的強大。他可以在幾秒鐘內處理千百萬位元組的日誌檔案,而且不需要任何程式設計技能。這種方式的優點是簡單、快速、可靠,並且可以輕鬆地在不同的機器上執行。
命令鏈與自訂程式
如果不想用 Unix 命令鏈(The chain of Unix commands),你也可以編寫一個簡單的程式來完成同樣的工作。例如在 Ruby 中,他看起來可能像這樣:
counts = Hash.new(0) # 1
File.open('/var/log/nginx/access.log') do |file|
file.each do |line|
url = line.split[6] # 2
counts[url] += 1 # 3
end
end
top5 = counts.map{|url, count| [count, url] }.sort.reverse[0...5] # 4
top5.each{|count, url| puts "#{count} #{url}" } # 5
這個程式不如 Unix 命令鏈那麼簡潔,但它也能完成相同的工作。這個程式的優點是更容易讀懂,並且可以更容易地擴展。例如,如果你想要將這個程式改為計算不同的統計數據,或者從不同的日誌檔案中讀取數據,這樣的修改在自訂程式中比在 Unix 命令鏈中更容易。
排序與記憶體中聚合
我們探討了兩種計數 URL 出現次數的方法:一種是使用記憶體中的雜湊表,另一種是依賴排序來處理 URL 列表。
- 記憶體中的雜湊表:這種方法使用 Ruby 指令碼在記憶體中儲存一個 URL 的雜湊表,每個 URL 對應其出現次數。對於大多數中小型網站,這種方法非常有效,因為這些網站的不同 URL 數量通常較少,可以輕鬆存儲在 1GB 記憶體中。如果日誌中只有少量不同的 URL,這種方法所需的記憶體很少,並且即使在效能較差的電腦上也能正常運行。
- 排序方法:Unix管道則不依賴記憶體中的雜湊表,而是通過對 URL 列表的排序來處理,重複出現的 URL 會自然地聚集在一起。當工作集大於可用記憶體時,這種方法的優勢顯現出來。排序方法可以高效地使用磁碟空間,資料塊可以在記憶體中排序並寫入磁碟,然後多個排序好的段可以合併為更大的排序檔案。GNU Coreutils 中的 sort 程式能夠自動處理大於記憶體的資料集,並且可以利用多個 CPU 核進行並行排序,這使得 Unix 命令鏈能夠輕鬆處理大資料集,而不會耗盡記憶體。
對於工作集較小的情況,記憶體中的雜湊表方法簡單且高效。然而,當面臨較大的資料集時,排序方法更具優勢,因為它能夠高效利用磁碟和多核處理能力,不會受到記憶體限制的影響。每種方法都有其適用的情境,選擇哪種方法應根據具體的資料集大小和系統資源情況而定。
Unix 哲學
- 每個程序只做一件事:設計簡單的工具,專注於完成單一任務,並且將其做得很好。
- 程序應該能夠互相組合:使用簡單的、統一的輸入和輸出機制(如文本流)來讓程序互相合作。
- 快速原型:構建程序應該迅速而簡單,不斷迭代和改進。
- 簡潔性:設計簡單易用的工具,避免過度複雜化。
這些原則源於 Unix 管道(pipes)的設計理念,強調組合和重用簡單的工具來完成複雜的任務。Unix 哲學倡導的設計方法在現代軟體工程中依然具有重要的參考價值,特別是在敏捷開發和 DevOps 實踐中。
統一的介面
- 統一輸入和輸出:Unix程序通常通過標準輸入(stdin)和標準輸出(stdout)來進行數據的讀取和寫入。這使得程序能夠輕鬆地通過管道(pipes)進行連接,從而實現複雜的數據處理任務。
- ASCII文本格式:Unix程序普遍使用ASCII文本作為數據交換的格式,這種格式簡單且易於解析,便於不同程序之間的互操作。這種做法雖然有時不夠精確,但對於大多數應用場景是有效的。
- 分離和組合數據:將複雜的數據處理任務分解為簡單的、可重用的小工具,每個工具只做一件事,並且這些工具可以通過管道進行組合來完成複雜的任務。
- 數據格式的兼容性:Unix工具可以處理多種數據格式,這使得不同來源的數據可以被統一處理,從而避免了數據碎片化(Balkanization of data)的問題。
- 實例與應用:這些原則在Unix工具的實踐中得到了廣泛應用,如使用awk來解析文本、sort來排序、uniq來去重等工具組合使用。
這些設計原則使得Unix系統在數據處理和軟體開發中具有高度的靈活性和可擴展性。
將邏輯與連接分離開來
- 標準輸入和標準輸出:Unix工具利用標準輸入和標準輸出來讀取和寫入數據,這意味著程序可以通過管道將數據從一個程序傳遞到另一個程序,而不需要中間臨時文件。
- 靈活的數據處理:通過這種方式,可以輕鬆地將不同的工具組合起來完成複雜的數據處理任務。例如,將某個程序的stdout連接到另一個程序的stdin,可以構建一個處理數據的流水線(pipeline)。
- 避免中間臨時文件:這種方法避免了將數據寫入磁碟再讀取的過程,節省了時間和資源,提高了效率。
- 實例應用:例如,可以使用
cat命令將文件內容傳遞給grep命令進行搜索,再將結果傳遞給sort命令進行排序,這些操作通過管道一氣呵成。
這些原則和實踐使得Unix工具在數據處理和系統管理中極其強大和靈活。
透明和試驗
- 透明性:Unix工具的設計使其內部運作過程對用戶透明,用戶可以輕鬆地理解工具的工作方式。這種透明性增加了工具的可預測性和可靠性。
- 簡單的組合:Unix工具的簡單接口使其容易組合,允許用戶通過管道和重定向將多個工具組合成一個複雜的操作流程。例如,使用ls列出文件,通過管道傳遞給grep進行過濾,再傳遞給sort進行排序。
- 試驗和調試:Unix工具的簡單性使得用戶可以輕鬆地進行試驗和調試。用戶可以快速地構建和測試新的命令序列,並查看它們的效果。
- 不變性和函數式設計:Unix工具通常是無狀態的,這意味著它們不會改變輸入數據,只是產生輸出。這種不變性使得工具更容易理解和預測。
例如使用 awk 和 sed 進行文本處理,使用pipeline組合多個命令來完成複雜的任務。這些設計原則和實踐使得Unix工具在現代計算中依然具有重要的地位和價值。
MapReduce 和分散式檔案系統
MapReduce是一種高效處理大規模數據集的工具,設計上與Unix工具的組合方式類似,但目的是為了在分散式環境中處理海量數據。MapReduce包含兩個主要階段:Map階段和Reduce階段,分別負責數據的分割與處理。
MapReduce使用標準輸入(stdin)和標準輸出(stdout)來進行數據的讀取和寫入,這使得其操作方式與Unix工具相似。然而,MapReduce的設計目的是在分散式環境下進行數據處理,特別適合處理需要大量計算資源的大數據分析任務,如網頁索引、社交網絡分析等。
Hadoop分散式檔案系統(HDFS)是MapReduce框架中的核心組件,用於存儲和管理大規模數據集。HDFS通過將數據分塊並分佈式存儲來提高數據的可靠性和訪問效率,能夠處理petabyte級別的大數據。它具有高度的容錯性,即使在硬件故障的情況下也能保持數據的完整性,並且提供高吞吐量的數據存取,非常適合大數據分析和處理任務。
除了HDFS,還有其他分散式檔案系統,如GlusterFS和Quantcast檔案系統(QFS),這些系統在特定應用場合下也有各自的優勢。MapReduce可以跨多個節點並行處理數據,通過使用Mapper和Reducer來實現數據的分割和匯總,展示了其在大數據處理中的強大功能和靈活性。
MapReduce 作業的執行
MapReduce是一個重要的框架設計,用於處理和分析海量數據。以下是執行過程中的關鍵步驟和原則:
- 資料分割:首先,將需要處理的大數據集分割成多個小塊,這些小塊可以被分配到不同的節點進行並行處理。
- Map階段:在這個階段,每個小塊數據被分配到一個Mapper節點。Mapper會讀取數據,並將其轉換為一組鍵值對(key-value pairs)。這個過程中的輸入和輸出都是鍵值對。
- Shuffle和Sort:在Map階段完成後,框架會將所有Mapper輸出的鍵值對進行分類和排序,將相同鍵的值組合在一起,準備進行下一步的處理。
- Reduce階段:在這個階段,分類和排序後的鍵值對會被傳送到Reducer節點。Reducer負責對這些鍵值對進行匯總和處理,最終生成輸出結果。
- 輸出結果:Reducer完成處理後,最終的結果會被寫入分散式檔案系統,如HDFS,用於後續的數據分析或查詢。
這些步驟展示了MapReduce如何通過分割、並行處理和匯總數據,有效地處理大規模數據集。這種方法允許MapReduce在多個節點上同時執行,提高了數據處理的效率和速度。
MapReduce 的分散式執行
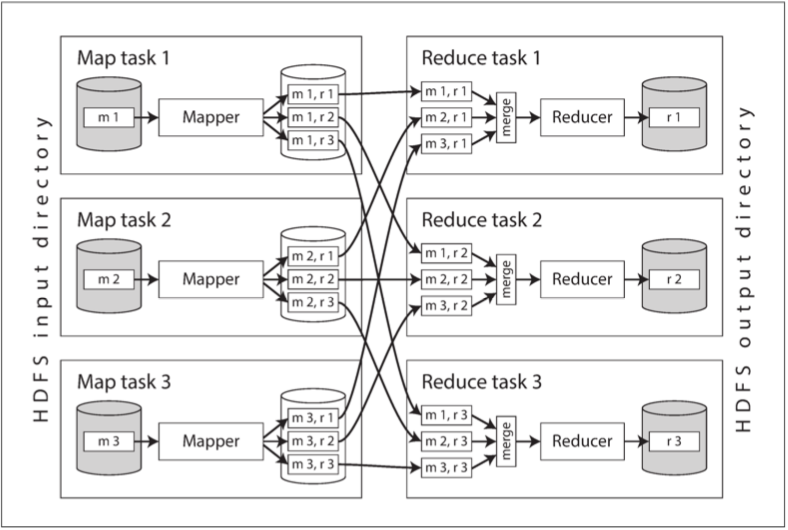
圖 10-1 顯示了 Hadoop MapReduce 作業的分散式執行過程。在這個過程中,MapReduce 框架將大數據集分割成多個小塊,並將這些小塊分配到不同的節點上進行並行處理。每個節點上運行的 Mapper 和 Reducer 負責處理數據,並將結果寫入分散式檔案系統。這種分散式執行方式使得 MapReduce 能夠高效地處理大規模數據集,並實現高吞吐量和低延遲。
Reduce-Side 的 Joins 跟 Grouping
Reduce-side的Join和Grouping操作在MapReduce框架中有重要的應用。這些操作主要在Reducers上完成,利用Mapper生成的key-value pairs進行處理。在這種方法中,Mapper先對數據進行初步處理,然後將結果發送到Reducer。Reducer接收來自不同Mapper的數據,對其進行匯總和處理,從而完成最終的join和grouping操作。
例如,在分析使用者活動事件時,可以將用戶的活動數據和用戶資料進行join操作。首先,Mapper將這些數據根據用戶ID進行標記,然後Reducer接收並根據用戶ID進行匯總,完成數據的結合。
此外,在進行Grouping操作時,Reducer會將具有相同key的數據聚集在一起進行處理。這種方法常用於需要根據特定字段進行分組的場景,如統計用戶行為、按類別匯總數據等。
在處理偏斜的情況下,MapReduce提供了一些優化策略,如在Mapper階段對數據進行預分配,或者在Reducer階段動態調整數據分配,以確保負載平衡,避免某些Reducer過載。
這些操作使得MapReduce能夠高效地處理和分析大規模數據集,特別是在需要進行複雜的數據連接和分組的場景中,展示了其強大的數據處理能力。
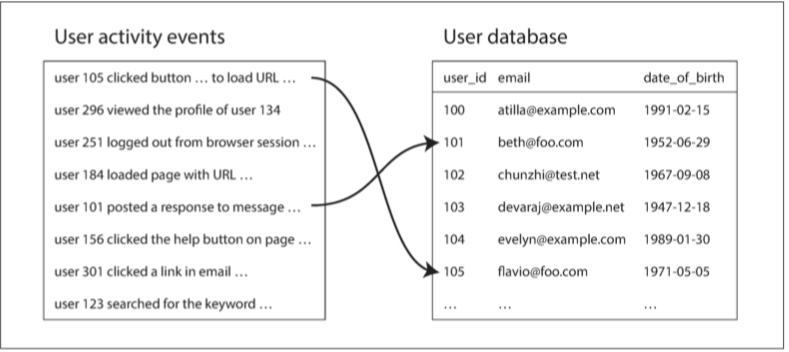
圖 10-2 給出了一個批處理作業中連線的典型例子。左側是事件日誌,描述登入使用者在網站上做的事情,右側是使用者資料庫。你可以將此示例看作是星型模式的一部分:事件日誌是事實表,使用者資料庫是其中的一個維度。
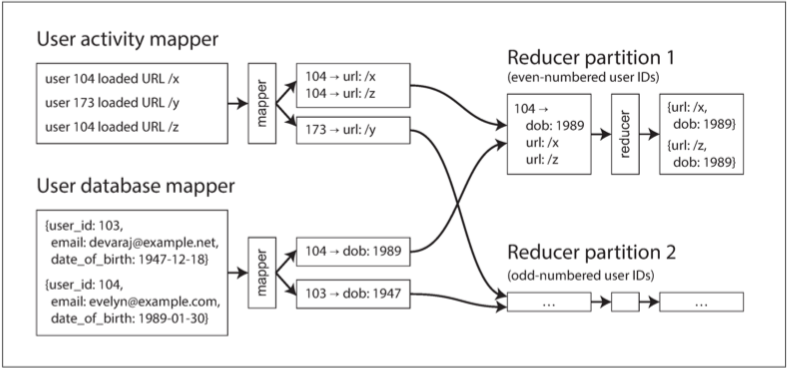
圖 10-3 在使用者 ID 上進行的 Reduce 端連線。如果輸入資料集分割槽為多個檔案,則每個分割槽都會被多個 Mapper 並行處理。
Map-Side Joins
在Map-Side Join中,數據連接的主要工作是在Mapper階段完成的,而不是在Reducer階段。這種方法適合於輸入數據中的某一部分較小且可以完全載入Mapper的記憶體的情況。這樣做的好處是可以減少數據傳輸的開銷,提高處理效率。
這種方法的執行過程包括:
- 數據分區:將大數據集劃分成多個分區,每個分區分配給不同的Mapper節點進行處理。小數據集則複製到所有的Mapper節點。
- 讀取和連接:每個Mapper讀取自己的數據分區,並將其與小數據集進行連接操作,生成最終的連接結果。
- 輸出結果:連接操作完成後,Mapper直接輸出最終的結果,無需進一步的Reducer處理。
這種方法適用於兩種特定情況:
- Broadcast Join:將小數據集廣播到所有Mapper節點,適用於小數據集與大數據集的連接。
- Partitioned Hash Join:大數據集和小數據集按照相同的鍵進行分區,每個分區的數據在對應的Mapper節點上進行連接。
這些方法能夠有效地減少數據傳輸和Reducer的負擔,提升整體數據處理的效率。在實際應用中,這些方法常用於數據量較大但分佈均勻,且某些數據集較小的場景。
批次處理工作流的輸出
我們已經討論了幾個關於執行MapReduce作業的workflows的各種實踐方法,但還需要了解它們的輸出結果。批次處理產生的結果是什麼樣的呢?通常情況下,批次處理的輸出涉及數據的持久化存儲。
建構搜尋索引
Google曾經使用MapReduce來建立搜索索引,這是一個很好的例子。MapReduce通過處理大量的文檔數據,生成索引結構,這些索引可以快速地支持搜索查詢。這個過程展示了MapReduce在處理大數據方面的強大能力和靈活性。
Google最初使用MapReduce是為了建立和更新搜索索引。這個過程涉及多個MapReduce作業,每個作業處理不同部分的數據。儘管Google後來不再使用MapReduce來實現這個目的,但這個過程展示了MapReduce的應用潛力。Hadoop MapReduce仍然是Lucene/Solr構建索引的一種方法。
在這個過程中,我們需要將文件集合進行全文檢索索引。每個MapReduce作業生成一個唯一的document ID,這些ID用來跟踪每個文檔。每個reducer都負責處理一部分文檔,並將結果存儲在document-partitioned索引中。這樣,我們可以利用MapReduce來批量建立和更新搜索索引。
鍵值儲存作為批次處理的輸出
另一個常見的批次處理workflow輸出是鍵值存儲。例如,批次處理可以將處理後的數據寫入到分散式鍵值存儲系統中,以便後續的快速查詢和檢索。這些系統如HBase、Cassandra等,可以在分佈式環境中提供高效的數據訪問。
正如前面提到的join時所探討的,鍵值儲存結合MapReduce作業非常適合處理需要快速查詢的數據。通過使用鍵值儲存系統,我們可以實現高效的數據讀取和寫入操作,並且這些操作可以被擴展到大型數據集。
批次處理輸出的哲學
批次處理輸出的哲學基於Unix的原則,即數據流的處理應該是可預測和可重複的。MapReduce框架的設計哲學強調了數據的不可變性和處理步驟的透明性。這些原則幫助確保了批次處理的可靠性和可擴展性。
透過將輸入視為不可變的,MapReduce能夠更好地處理大數據,並避免數據處理中的副作用。這些設計原則不僅提升了數據處理的效率,也使得數據處理的過程更加簡潔和透明。
在批次處理的過程中,常見的挑戰包括數據分區、負載均衡、故障恢復等。MapReduce框架提供了一些內建的機制來應對這些挑戰,比如透過重試機制來處理節點故障,通過數據分區來實現負載均衡等。
這些內容展示了批次處理工作流在MapReduce框架中的應用及其重要性,並強調了通過良好的設計原則來應對大數據處理中的挑戰。
結論
本章探討了批次處理這個主題。我們首先研究了Unix工具,如 awk 、 grep 和 sort ,並理解這些工具的設計原則如何應用到MapReduce以及dataflow引擎中。其中特別強調了數據輸入應該是不可變的(immutable),輸出則應該是從無到有的(一次性生成的)。
在Unix世界中,files和pipes是數據交換和處理的主要介面;在MapReduce中,dataflow引擎則使用它們自己的pipe-like機制來實現類似的數據流處理模式。這些模式在解決大數據處理和分析中的批次處理需求方面起到了關鍵作用,但伴隨著批次處理的過程也帶來了幾個需要解決的重要問題。
分區
在MapReduce中,Mappers根據輸入鍵來劃分區域,Mappers的輸出被重新分區,並排入每個Reducer的處理隊列中。每個Reducer負責處理特定分區的數據,這樣可以確保具有相同key的所有數據都被發送到同一個Reducer。
客錯
MapReduce會頻繁地寫入數據到磁碟,這使得它在面對任務失敗時具有高容錯性。而不常發生錯誤的Dataflow引擎通常依賴於更複雜的技術來保持資料的一致性,這需要對每個操作進行細粒度的監控和管理,以確保資料的準確性。
我們詳細探討了幾種MapReduce的join演算法,其中大多數是在MPP資料庫和dataflow引擎的商業應用中實現的。它們的設計目標是如何在工作負載下提供高效的數據處理。
Sort-merge joins
這種方法在joined的輸入鍵中經常使用,mapper將數據根據join key進行排序,並將相同鍵值的數據發送到相同的reducer進行合併處理,最終完成數據的join操作。
Broadcast hash joins
在Broadcast hash joins中,其中一個數據集很小,因此可以被複製到每個mapper中進行處理。這樣,所有mapper都可以獨立地對小數據集進行hash並與大的數據集進行join操作。
Partitioned hash joins
Partitioned hash joins根據相同的鍵將輸入數據集分區。每個mapper處理自己的分區,這樣可以在mapper階段完成大部分的join操作,減少數據在reducer之間傳輸的需求。
這些不同類型的joins和批次處理技術展示了MapReduce在大數據處理中的靈活性和強大功能。根據具體的應用場景選擇合適的技術,可以顯著提高數據處理的效率和可靠性。