Ch7: 交易
ACID
交易所提供的安全保證
一組能夠精確描述資料庫容錯機制的術語
Atomicity: 原子性
Consistency: 一致性
Isolation: 隔離性
Durability: 持久性
實際上不同資料庫的ACID實作並不完全相同,隔離性的含義有很多含糊之處,
當一個系統宣稱他是 "ACID相容" 的時候,
你實際上無法確切知道他到提供了什麼樣的保證,
ACID基本上已經變成一種行銷術語了
不符合ACID標準的系統有時稱為BASE
Basically Available: 基本可用
Soft State: 軟狀態
Eventual consistency: 最終一致性
這些比ACID的定義更模糊,幾乎可以代表任何你想要的東西
Atomicity 原子性
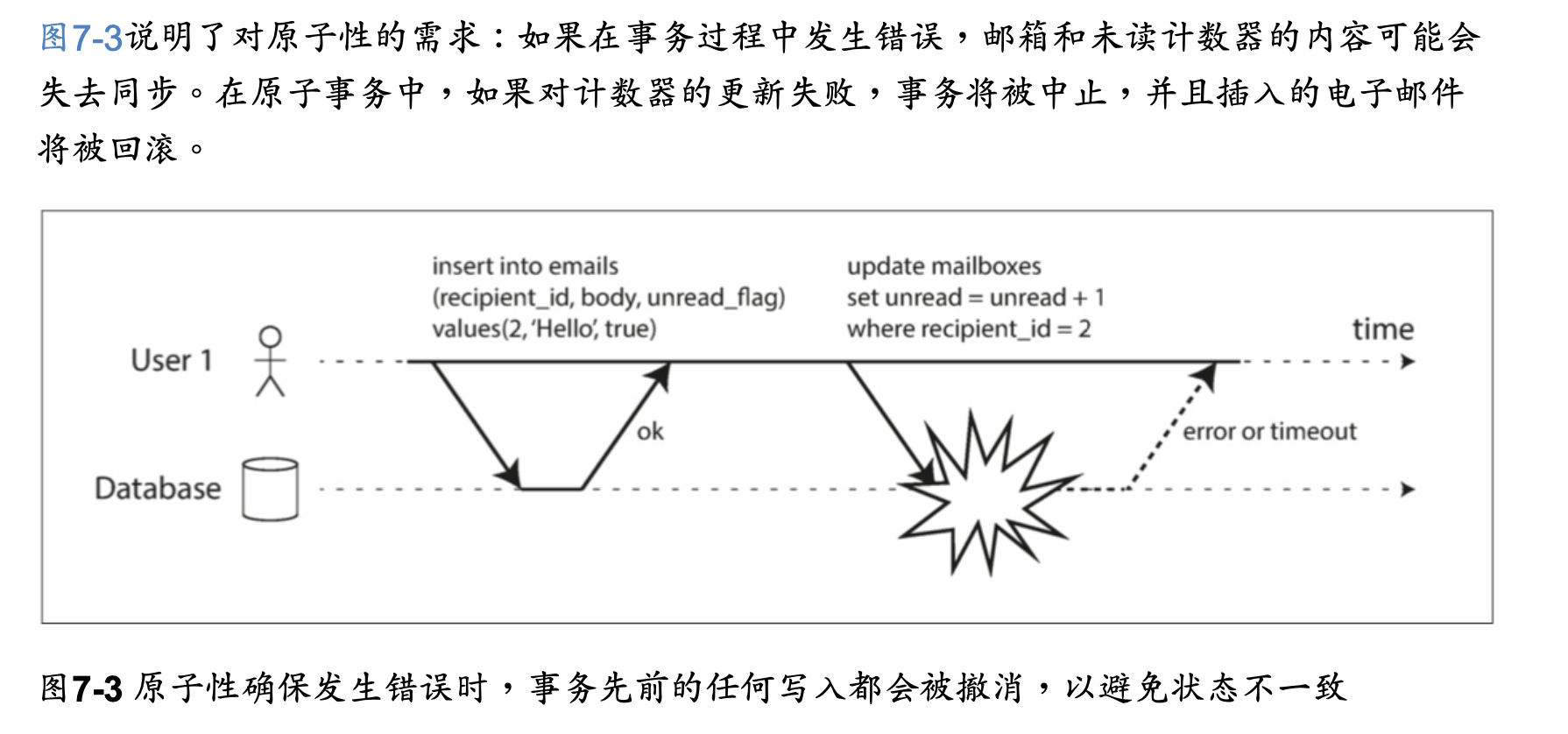
ACID的原子性描述了,當客戶想進行多次寫入,但在一些寫操作處理完之後出現故障的情況。
例如進程崩潰,網絡連接中斷,磁盤變滿或者某種完整性約束被違反。
如果這些寫操作被分組到一個原子交易中,並且該交易由於錯誤而不能完成(提交),
則該交易將被中止,並且資料庫必須丟棄或撤消該交易中迄今為止所做的任何寫入。
定義特徵是:能夠在錯誤時中止交易,丟棄該交易進行的所有寫入變更的能力。
或許中止性(abortability)是更好的術語,但本書將繼續使用原子性,因為這是慣用詞。
all-or-nothing
Consistency 一致性
ACID一致性的概念是,對數據的一組特定陳述必須始終成立。即不變量(invariants)。
例如,在會計系統中,所有賬戶整體上必須借貸相抵。
一些特定類型的不變量可以由資料庫檢查,例如外鍵約束或唯一約束,
但是一般來說,是應用程式來定義什麼樣的數據是有效的,什麼樣是無效的,資料庫只管儲存。
應用可能依賴資料庫的原子性和隔離性屬性來實現一致性,但這並不僅取決於資料庫。
因此,字母C不屬於ACID。
Isolation 隔離性
大多數資料庫都會同時被多個客戶端訪問。
如果它們各自讀寫資料庫的不同部分,這是沒有問題的,
但是如果它們訪問相同的資料庫記錄,則可能會遇到並發問題(競爭條件(race conditions))。
ACID意義上的隔離性意味著,同時執行的交易是相互隔離的:它們不能相互冒犯。
Durability 持久性
資料庫系統的目的是,提供一個安全的地方存儲數據,而不用擔心丟失。
持久性是一個承諾,即一旦交易成功完成,即使發生硬體故障或資料庫崩潰,寫入的任何數據也不會丟失。
在單節點資料庫中,持久性通常意味著數據已被寫入非揮發性性儲存設備,如硬盤或SSD。
它通常還包括預寫日誌或類似的文件(參閱“讓B樹更可靠”),以便在磁盤上的數據結構損壞時 進行恢復
在帶複製的資料庫中,持久性可能意味著數據已成功複製到一些節點。為了提供持久性保證,資料庫必須等到這些寫入或複製完成後,才能報告交易成功提交。
完美的持久性是不存在的:如果所有硬盤和所有備份同時被銷毀,那顯然沒有任何資料庫能救得了你。
在歷史上,持久性意味著寫入歸檔磁帶。後來它被理解為寫入硬盤或SSD。
最近它已經適應了“複製(replication)”的新內涵。哪種實現更好一些?
真相是,沒有什麼是完美的:
在實踐中,沒有一種技術可以提供絕對保證。
只有各種降低風險的技術,包括寫入磁盤,複製到遠程機器和備份——它們可以且應該一起使用。
與往常一樣,最好抱著懷疑的態度接受任何理論上的“保證”。
單物件和多物件操作
假設你想同時修改多個對象(行,文檔,記錄)。
通常需要多對象交易(multi-object transaction) 來保持多塊數據同步。
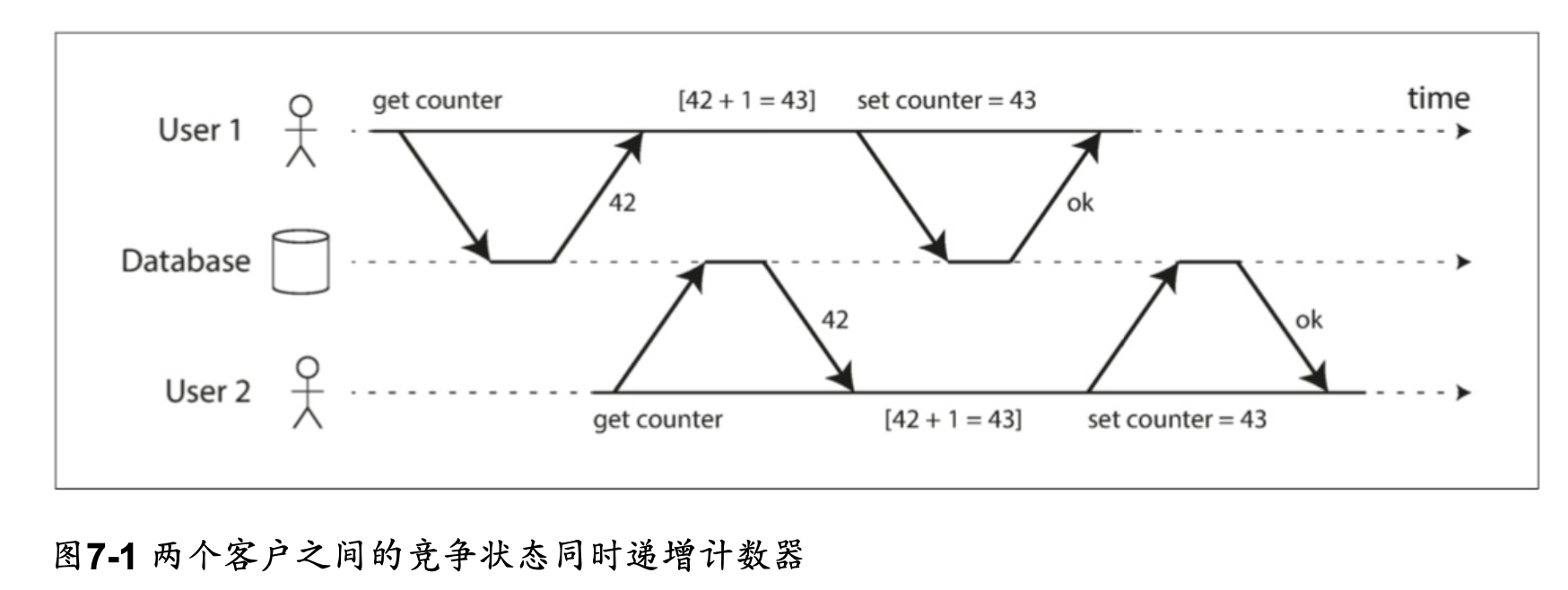
圖7-2展示了一個來自電子郵件應用的例子。
每當一個新消息寫入時,必須也增長未讀計數器,每當一個消息被標記為已讀時,也必須減少未讀計數器。
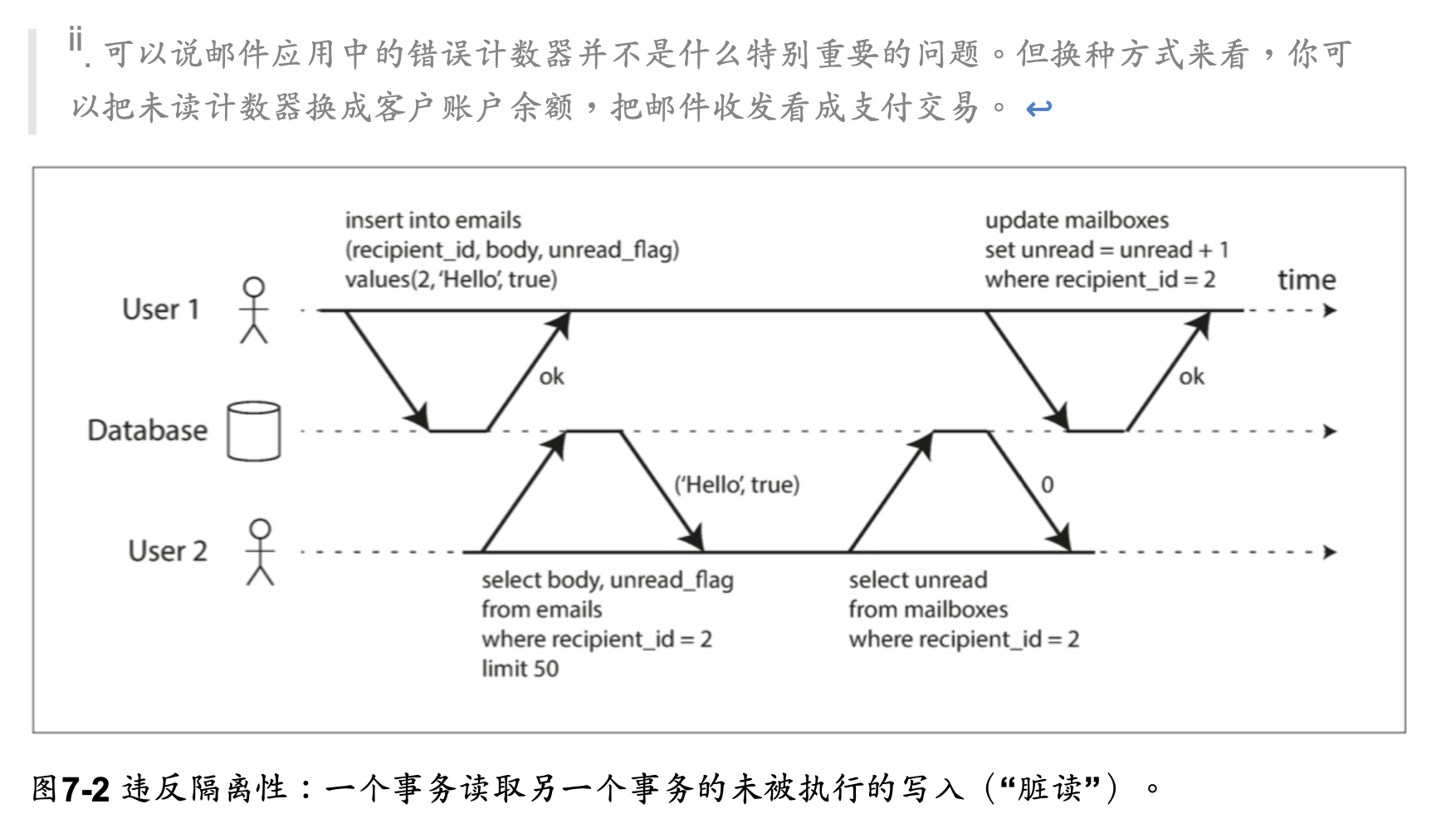
在關聯式資料庫中,通常基於客戶端與資料庫伺服器的TCP連接:在任何特定連接上,BEGIN TRANSACTION 和 COMMIT 語句之間的所有內容,被認為是同一交易的一部分
另一方面,許多非關聯資料庫並沒有將這些操作組合在一起的方法。
即使存在多對象API(例如,鍵值存儲可能具有在一個操作中更新幾個鍵的多重放置操作),
但這並不一定意味著它具有交易語義:該命令可能在一些鍵上成功,在其他的鍵上失敗,使資料庫處於部分更新的狀態。
單物件寫入
當單個對象發生改變時,原子性和隔離也是適用的。
例如,假設您正在向資料庫寫入一個 20KB的 JSON文檔:
- 如果在发送第一个10 KB之后网络连接中断,数据库是否存储了不可解析的10KB JSON 片段?
- 如果在数据库正在覆盖磁盘上的前一个值的过程中电源发生故障,是否最终将新旧值拼接在一起?
- 如果另一个客户端在写入过程中读取该文档,是否会看到部分更新的值?
原子性可以通過使用日誌來實現崩潰恢復(參閱“使B樹可靠”),
並且可以使用每個對象上的鎖來實現隔離(每次只允許一個線程訪問對象)。
一些資料庫也提供更複雜的原子操作,例如自增操作,這樣就不再需要像圖7-1那樣的讀取-修改-寫入序列了。
UPDATE counters SET value = value + 1 WHERE key = 'foo';
同樣流行的是比較和設置(CAS, compare-and-set)操作,當值沒有並發被其他人修改過時,才允許執行寫操作。
-- 根据数据库的实现情况,这可能也可能不安全
UPDATE wiki_pages SET content = '新内容'
WHERE id = 1234 AND content = '旧内容';
這些單對象操作很有用,因為它們可以防止在多個客戶端嘗試同時寫入同一個對象時丟失更新(參閱“防止丟失更新”)。
但它們不是通常意義上的交易。CAS以及其他單一對象操作被稱為“輕量級交易”。
交易通常被理解為,將多個對象上的多個操作合併為一個執行單元的機制。
多物件交易的必要性
許多分布式數據存儲已經放棄了多對象交易,因為多對象交易很難跨分區實現,
而且在需要高可用性或高性能的情況下,它們可能會礙事。
但說到底,在分布式資料庫中實現交易,並沒有什麼根本性的障礙。
第9章將討論分布式交易的實現。
我們是否需要多對象交易?是否有可能只用鍵值數據模型和單對象操作來實現任何應用程序?
有一些場景中,單對象插入,更新和刪除是足夠的。但是許多其他場景需要協調寫入幾個不同的對象:
- 在關聯數據模型中,一個表中的行通常具有對另一個表中的行的外鍵引用。(類似的是,在一個圖數據模型中,一個頂點有著到其他頂點的邊)。多對象交易使你确信這些引用始終有效:當插入幾個相互引用的記錄時,外鍵必須是正確的,最新的,不然數據就沒有意義。
- 在文檔數據模型中,需要一起更新的字段通常在同一個文檔中,這被視為單個對象——更新單個文檔時不需要多對象交易。但是,缺乏連接功能的文檔資料庫會鼓勵非規範化(參閱“關聯式資料庫與文檔資料庫在今日的對比”)。當需要更新非規範化的信息時,如圖7-2 所示,需要一次更新多個文檔。交易在這種情況下非常有用,可以防止非規範化的數據不同步。
- 在具有二級索引的資料庫中(除了純粹的鍵值存儲以外幾乎都有),每次更改值時都需要更新索引。從交易角度來看,這些索引是不同的資料庫對象:例如,如果沒有交易隔離性,記錄可能出現在一個索引中,但沒有出現在另一個索引中,因為第二個索引的更新還沒有發生。
這些應用仍然可以在沒有交易的情況下實現。
然而,沒有原子性,錯誤處理就要複雜得多,缺乏隔離性,就會導致並發問題。
我們將在“弱隔離級別”中討論這些問題,並在第12章中探討其他方法。
處理錯誤和中止
交易的一個關鍵特性是,如果發生錯誤,它可以中止並安全地重試,
中止的重點就是允許安全的重試。
ACID資料庫基於這樣的 哲學:如果資料庫有違反其原子性,隔離性或持久性的危險,則寧願完全放棄交易,而不是留下半成品。
然而並不是所有的系統都遵循這個哲學。特別是具有無主複製的數據存儲,主要是在“盡力而 為”的基礎上進行工作。
儘管重試一個中止的交易是一個簡單而有效的錯誤處理機制,但它並不完美:
- 如果交易實際上成功了,但是在伺服器試圖向客戶端確認提交成功時網絡發生故障(所以客戶端認為提交失敗了),那麼重試交易會導致交易被執行兩次——除非你有一個額外的應用級除重機制。
- 如果錯誤是由於負載過大造成的,則重試交易將使問題變得更糟,而不是更好。為了避免這種正反饋循環,可以限制重試次數,使用指數退避算法,並單獨處理與過載相關的錯誤(如果允許)。
- 僅在臨時性錯誤(例如,由於死鎖,異常情況,臨時性網絡中斷和故障切換)後才值得重試。在發生永久性錯誤(例如,違反約束)之後重試是毫無意義的。
- 如果交易在資料庫之外也有副作用,即使交易被中止,也可能發生這些副作用。例如,如果你正在發送電子郵件,那你肯定不希望每次重試交易時都重新發送電子郵件。
- 如果你想確保幾個不同的系統一起提交或放棄,二階段提交(2PC, two-phase commit)可以提供幫助(“原子提交和兩階段提交(2PC)”中將討論這個問題)。
- 如果客戶端進程在重試中失效,任何試圖寫入資料庫的數據都將丟失。
弱隔離級別
当一个事务读取由另一个事务同时修改的数据时,或者当两个事务试图同时修改相同的数据时,并发问题(竞争条件)才会出现。
并发BUG很难通过测试找到,因为这样的错误只有在特殊时机下才会触发。这样的时机可能很少,通常很难重现。
并发性也很难推理,特别是在大型应用中,你不一定知道哪些其他代码正在访问数据库。
在一次只有一个用户时,应用开发已经很麻烦了,有许多并发用户使得它更加困难,因为任何一个数据都可能随时改变。
出于这个原因,数据库一直试图通过提供事务隔离(transaction isolation)来隐藏应用程序开发者的并发问题。
从理论上讲,隔离可以通过假装没有并发发生,让你的生活更加轻松: 可序列化(serializable)的隔离等级意味着数据库保证事务的效果与连续运行(即一次一个,没有任何并发)是一样的。
实际上不幸的是:隔离并没有那么简单。可序列化会有性能损失,许多数据库不愿意支付这个代价。
因此,系统通常使用较弱的隔离级别来防止一部分,而不是全部的并发问题。
这些隔离级别难以理解,并且会导致微妙的错误,但是它们仍然在实践中被使用
比起盲目地依赖工具,我们应该对存在的并发问题的种类,以及如何防止这些问题有深入的理解。
然后就可以使用我们所掌握的工具来构建可靠和正确的应用程序。
在本节中,我们将看几个在实践中使用的弱(不可串行化(nonserializable))隔离级别, 并详细讨论哪种竞争条件可能发生也可能不发生,以便您可以决定什么级别适合您的应用程序。 一旦我们完成了这个工作,我们将详细讨论可串行性(请参阅“可序列化”)
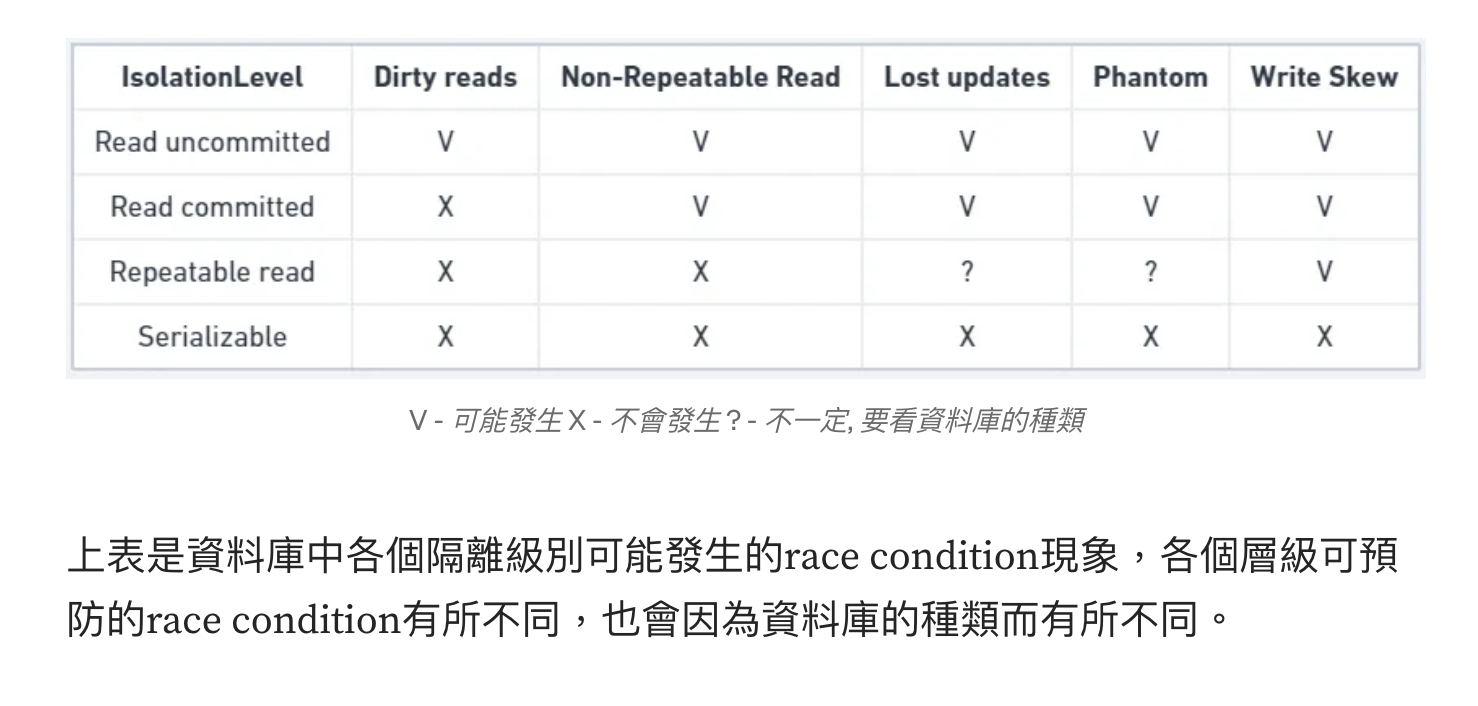
讀已提交 Read Committed
- 从数据库读时,只能看到已提交的数据(没有脏读(dirty reads))。
- 写入数据库时,只会覆盖已经写入的数据(没有脏写(dirty writes))。
某些数据库支持甚至更弱的隔离级别,称为读未提交(Read uncommitted)。它可以防止脏写,但不防止脏读。
無髒讀 No dirty reads
dirty reads: 一個交易可以讀取另外一個交易尚未 commit 的資料
防止脏读。这意味着事务的任何写入操作只有在该事务提交时才能被其他人看到(然后所有的写入操作都会立即变得可见)
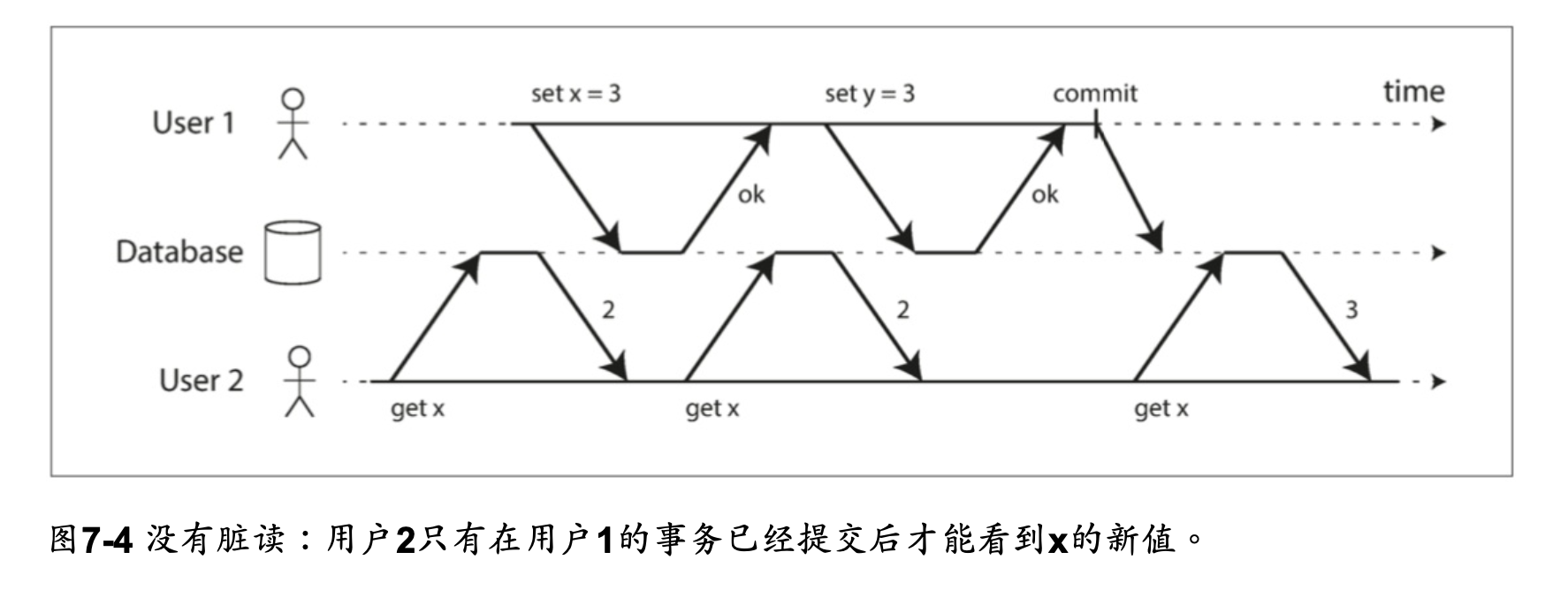
为什么要防止脏读,有几个原因:
- 看到处于部分更新状态的数据库会让用户感到困惑
- 可能会看到稍后需要回滚的数据
無髒寫 No dirty writes
后面的写入覆盖一个尚未提交的值
在读已提交的隔离级别上运行的事务必须防止脏写,通常是延迟第二次写入,直到第一次写入事务提交或中止为止。
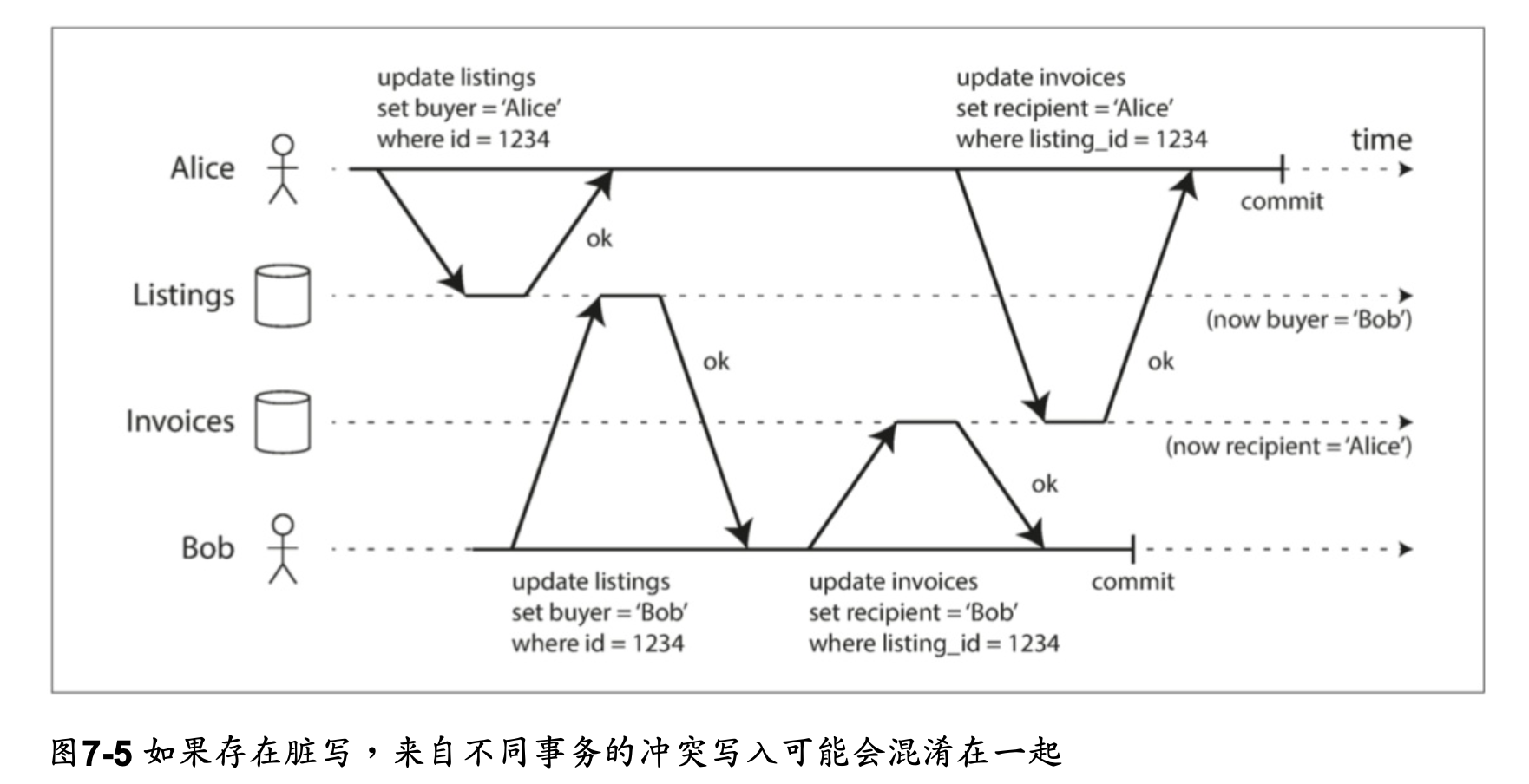
通过防止脏写,这个隔离级别避免了一些并发问题:
- 如果事务更新多个对象,脏写会导致不好的结果。例如,考虑 图7-5,图7-5 以一个二手车销售网站为例,Alice和Bob两个人同时试图购买同一辆车。购买汽车需要两次数据库 写入:网站上的商品列表需要更新,以反映买家的购买,销售发票需要发送给买家。在 图7-5的情况下,销售是属于Bob的(因为他成功更新了商品列表),但发票却寄送给了爱丽丝(因为她成功更新了发票表)。读已提交会阻止这样这样的事故。
- 但是,提交读取并不能防止图7-1中两个计数器增量之间的竞争状态。在这种情况下,第二次写入发生在第一个事务提交后,所以它不是一个脏写。这仍然是不正确的,但是出于不同的原因,在“防止更新丢失”中将讨论如何使这种计数器增量安全。
讀已提交的實作
读已提交是一个非常流行的隔离级别。这是Oracle 11g,PostgreSQL,SQL Server 2012, MemSQL和其他许多数据库的默认设置
最常见的情况是,数据库通过使用行锁(row-level lock) 来防止脏写
如何防止脏读?一种选择是使用相同的锁,并要求任何想要读取对象的事务来简单地获取该锁
但是要求读锁的办法在实践中效果并不好。因为一个长时间运行的写入事务会迫使许多只读
事务等到这个慢写入事务完成。这会损失只读事务的响应时间,并且不利于可操作性
大多数数据库使用图7-4的方式防止脏读:对于写入的每个对象,数据库都会记住旧的已提交值,和由当前持有写入锁的事务设置的新值。
当事务正在进行时,任何其他读取对象的事务都会拿到旧值。只有当新值提交后,事务才会切换到读取新值。
快照隔離和可重複讀取 snapshot isolation and repeatable read
Read Committed 的隔離級別雖然可以防止 dirty read, dirty write,但仍有會產生併發錯誤的狀況
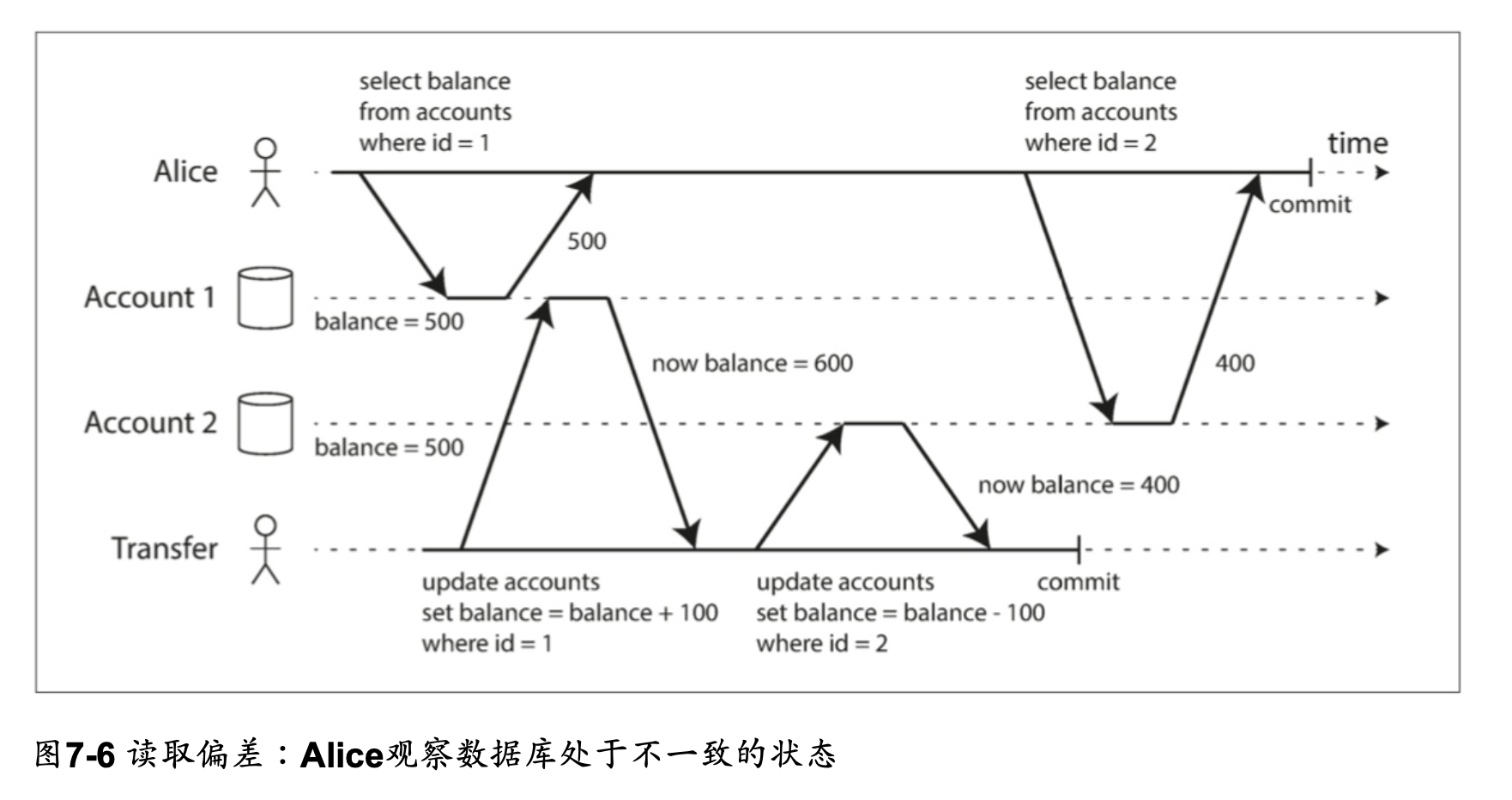
這種異常被稱為不可重複讀(nonrepeatable read)或讀取偏差(read skew)
- non-repeatable read 是指在同一交易中,多次讀取同一筆數據時,結果可能會因為其他交易的修改而不一致
- 在同一個交易中的不同時間點反覆讀取 account 1 的餘額,會出現不醫治的狀況 --> non-repeatable read
- read committed 層級的隔離保證是允許 read skew,但在 repeatable read 的隔離等級就必須要能防止 read skew
對於 Alice 的情況,這不是一個長期持續的問題。因為如果她幾秒鐘後刷新銀行網站的頁面,
她很可能會看到一致的帳戶餘額。但是有些情況下,不能容忍這種暫時的不一致:
- 備份: 進行備份需要複製整個資料庫,對大型資料庫而言可能需要花費數小時才能完成。備份進程運行時,資料庫仍然會接受寫入操作。因此備份可能會包含一些舊的部分和一些新的部分。如果從這樣的備份中恢復,那麼不一致(如消失的錢)就會變成永久的。
- 分析查詢和完整性檢查: 有時,您可能需要運行一個查詢,掃描大部分的資料庫。這樣的查詢在分析中很常見(參閱“交易處理或分析?”),也可能是定期完整性檢查(即監視數據損壞)的一部分。如果這些查詢在不同時間點觀察資料庫的不同部分,則可能會返回毫無意義的結果。
快照隔離(snapshot isolation)是這個問題最常見的解決方案
快照隔離對長時間運行的只讀查詢(如備份和分析)非常有用。
如果查詢的數據在查詢執行的同時發生變化,則很難理解查詢的含義。
當一個交易可以看到資料庫在某個特定時間點凍結時的一致快照,理解起來就很容易了。
快照隔離是一個流行的功能:PostgreSQL,使用 InnoDB 引擎的 MySQL,Oracle,SQL Server 等都支持。
快照隔離的實作
快照隔離的實現通常使用寫鎖來防止髒寫
但是讀取不需要任何鎖定
從性能的角度來看,快照隔離的一個關鍵原則是:讀不阻塞寫,寫不阻塞讀。
這允許資料庫在處理一致性快照上的長時間查詢時,可以正常地同時處理寫入操作。且兩者間沒有任何鎖定爭用。
為了實現快照隔離,資料庫必須可能保留一個對象的幾個不同的提交版本,
因為各種正在進行的交易可能需要看到資料庫在不同的時間點的狀態。
因為它並排維護著多個版本的對象,所以這種技術被稱為多版本並發控制(MVCC, multi-version concurrency control)。
如果一個資料庫只需要提供讀已提交的隔離級別,而不提供快照隔離,那麼保留一個對象的兩個版本就足夠了:提交的版本和被覆蓋但尚未提交的版本(如此就能做到防止 dirty read 了)。
支持快照隔離的存儲引擎通常也使用 MVCC 來實現 read committed 隔離。
一種典型的方法是 read committed 為每個查詢使用單獨的快照,而快照隔離對整個交易使用相同的快照。
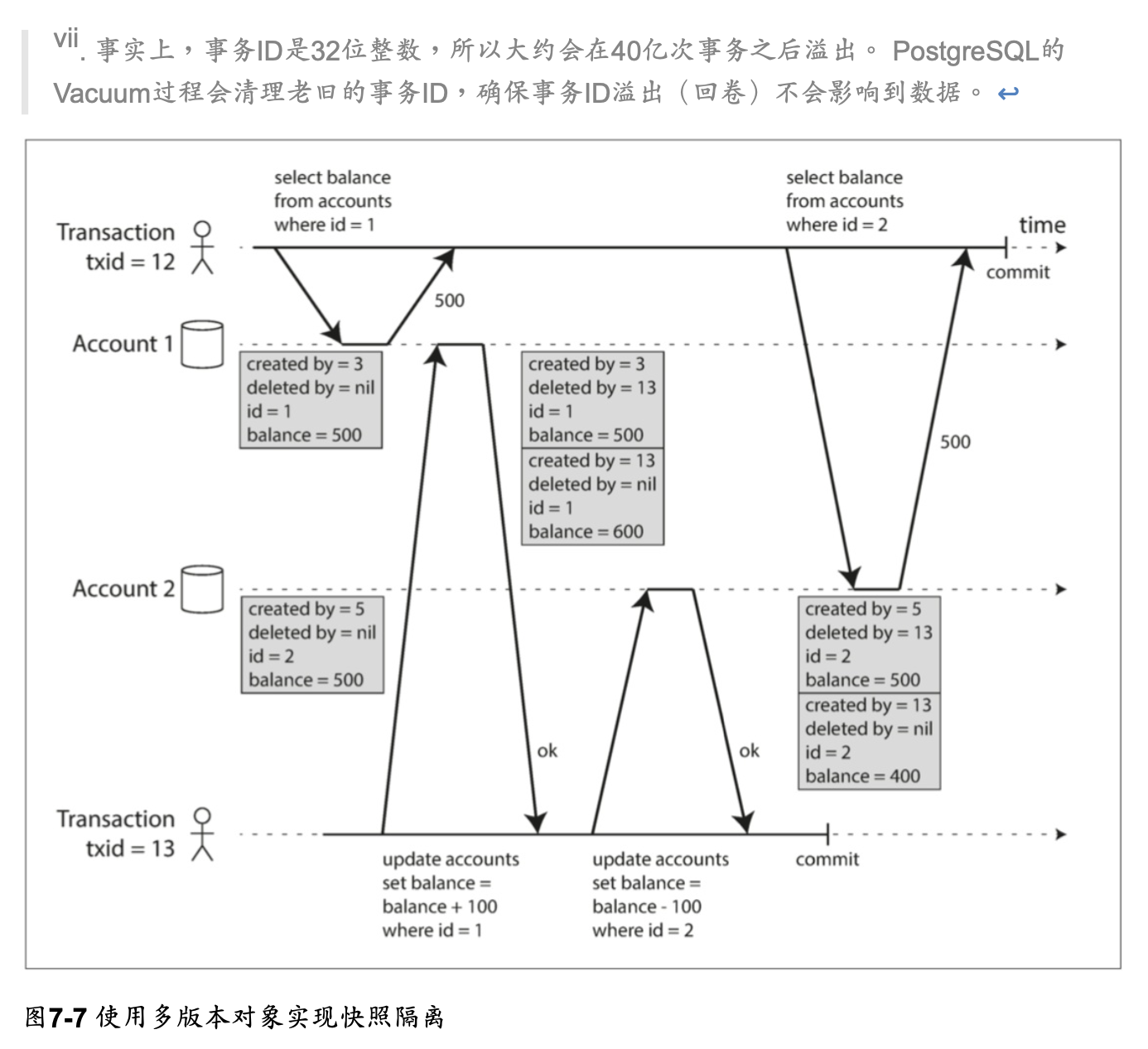
這是 PostgreSQL 中實現基於 MVCC 的快照隔離(其他實現類似)
當一個交易開始時,它被賦予一個唯一的,永遠增長的交易 ID (txid)
每當交易向資料庫寫入任何內容時,它所寫入的數據都會被標記上寫入者的交易 ID
透過 created_by 過 deleted_by 去紀錄交易 id, 確定沒有交易可以再訪問已刪除的數據時,資料庫中的垃圾收集過程會將所有帶有刪除標記的行移除,並釋放其空間
在 PostgreSQL 中, created_by 的實際名稱為 xmin,deleted_by 的實際名稱為 xmax
觀察一致性快照 (consistent snapshot) 的可見性規則
當一個交易從資料庫中讀取時,交易 ID 用於決定它可以看見哪些對象,看不見哪些對象。
通過仔細定義可見性規則,資料庫可以向應用程序呈現一致的資料庫快照。工作如下:
- 在每次交易開始時,資料庫列出當時所有其他(尚未提交或中止)的交易清單,即使之後提交了,這些交易的寫入也都會被忽略。
- 被中止交易所執行的任何寫入都將被忽略。
- 由具有較晚交易 ID (即,在當前交易開始之後開始的)的交易所做的任何寫入都被忽略,而不管這些交易是否已經提交。
- 所有其他寫入,對應用都是可見的。
這些規則適用於創建和刪除對象。
在圖 7-7 中,當交易 12 從帳戶 2 讀取時,它會看到 $500 的餘額,
因為 $500 餘額的刪除是由交易 13 完成的(根據規則 3,交易 12 看不到交易 13 執行的刪除),
且 400 美元記錄的創建也是不可見的(按照相同的規則)。
換句話說,如果以下兩個條件都成立,那麼一個資料物件對交易來講就是可見的:
- 當讀方交易開始時,創建物件的交易已經提交。
- 物件未被標記為刪除,或即使被標記為刪除,請求刪除的交易在讀交易開始時尚未提交。
長時間運行的交易可能會長時間使用快照,並繼續讀取(從其他交易的角度來看)早已被覆蓋或刪除的值。
由於從來不更新值,而是每次值改變時創建一個新的版本,資料庫可以在提供一致快照的同時只產生很小的額外開銷。
索引和快照隔離
索引如何在多版本資料庫中工作?
一種選擇是使索引簡單地指向對象的所有版本,並且需要索引查詢來過濾掉當前交易不可見的任何對象版本。
當垃圾收集刪除任何交易不再可見的舊對象版本時,相應的索引條目也可以被刪除。
許多實作細節決定了多版本併發控制的性能。
例如,如果同一物件的不同版本可以放入同一個page中,PostgreSQL 的優化可以避免更新索引
在 CouchDB,Datomic 和 LMDB 中使用另一種方法。
雖然它們也使用 B-tree,但它們使用的是一種"僅接受追加/寫時複製(append-only/copy-on-write)"的變體 P83,
它們在更新時不覆蓋樹的pages,而為每個修改頁面創建一份副本。
從父頁面直到樹根都會級聯更新,以指向它們子頁面的新版本。
任何不受寫入影響的頁面都不需要複製,並且保持不變。
使用 append-only 的 B-tree,每個寫入交易(或批次交易)都會創建一顆新的 B-tree root,
當創建時,從該特定樹根生長的樹就是資料庫的一個一致性快照。
這樣就不必根據交易 ID 過濾物件,因為後續寫入不能修改現有的 B-tree,只能創建新的樹根。
但這種方法也需要一個負責壓縮和垃圾回收的背景程序。
可重複讀取的命名混淆
快照隔離是一個有用的隔離級別,特別對於 readonly 交易而言。
但是,許多資料庫實作了它,卻用不同的名字來稱呼。
- 在 Oracle 中稱為可序列化(Serializable)的
- 在 PostgreSQL 和 MySQL 中稱為可重複讀(repeatable read)
這種命名混淆的原因是 SQL 標準沒有快照隔離的概念,因為標準是基於 System R 1975 年定義的隔離級別,那時候快照隔離尚未發明。
相反,它定義了可重複讀,表面上看起來與快照隔離很相似。
PostgreSQL 和 MySQL 稱其快照隔離級別為可重複讀(repeatable read),因為這樣符合標準要求,所以它們可以聲稱自己“標準兼容”。
不幸的是,SQL 標準對隔離級別的定義是有缺陷的——模糊,不精確,並不像標準應有的樣子獨立於實現。
有幾個資料庫實現了可重複讀,但它們實際提供的保證存在很大的差異,儘管表面上是標準化的。
在研究文獻【29,30】中已經有了可重複讀的正式定義,但大多數的實現並不能滿足這個正式定義。
最後,IBM DB2 的“可重複讀”所表示的是可序列化。
結果,搞到沒有人知道到底 repeatable read 究竟代表什麼意思了
防止更新丟失 lost update
除了 dirty read 談到的併發寫入錯誤之外, write-write conflict 還有一些其他的併發衝突問題, 其中最著名的是更新丟失 (lost update)
如圖 7-1 所示,以兩個併發計數器增量,
因為第二個寫入並不會包含第一個修改(後寫者勝),第一個寫入的更新就"被消失"了
- 增加計數器或更新帳戶餘額(需要讀取當前值,計算新值並寫回更新後的值)
- 對複合值做本地修改,例如,將元素添加到 JSON 文件中的一個列表(需要解析文件,進行更改並寫回修改的文件)
- 兩個使用者同時編輯一個 wiki page,每個用戶通過將整個頁面內容發送到伺服器來保存其更改,覆寫資料庫中當前的任何內容。
這是一個普遍的問題,所以已經開發了各種解決方案。
原子寫入操作
UPDATE counters SET value = value + 1 WHERE key = 'foo';
如果你的代碼可以用這些操作來表達,那這通常是最好的解決方案。這個指令在大多數關連式資料庫中是併發安全的
不需要再應用程式碼中自己實作 read-modify-write cycles
類似地,像 MongoDB 這樣的文件資料庫提供了對 JSON 文件的一部分進行本地修改的原子操作,
Redis 提供了修改數據結構(如優先佇列)的原子操作。
並不是所有的寫操作都可以用原子操作的方式來表達,例如 wiki 頁面的更新涉及到任意文本編輯,
但是在可以使用原子操作的情況下,它們通常是最好的選擇。
原子操作通常是透對讀取物件加上互斥所來實作。
這樣在更新完成之前沒有其他交易可以讀取它。這種技術有時被稱為游標穩定性(cursor stability)。
另一個選擇是簡單地強制所有的原子操作在單一線程上執行。
不幸的是,ORM 框架很容易意外地執行不安全的 read-modify-write cycles,
而不是使用資料庫提供的原子操作。
如果你知道自己在做什麼那當然不是問題,但它經常產生那種很難測出來的 Bug。
顯示加鎖
如果資料庫的內建的原子操作無法提供所需功能,防止丟失更新的另一個選擇是讓應用程式對欲更新的物件上鎖。
範例 7-1
BEGIN TRANSACTION;
SELECT *
FROM figures
WHERE name = 'robot'
AND game_id = 222
FOR UPDATE;
-- 检查玩家的操作是否有效,然后更新先前SELECT返回棋子的位置。
UPDATE figures
SET position = 'c4'
WHERE id = 1234;
COMMIT;
FOR UPDATE 子句告訴資料庫應該對該查詢返回的所有行上鎖。
這是有效的,但要做對,你需要仔細考慮應用邏輯。忘記在程式碼某處加鎖很容易引入競爭條件。
自動檢測
原子操作和鎖是通過強制 read-modify-write cycles 按順序發生來防止丟失更新。
另一種方法是允許它們並行執行,如果交易管理器檢測到丟失更新,則中止交易並強制它們重試其read-modify-write cycles。
資料庫借助快照隔離來高效執行檢查
- PostgreSQL 的 repeatable read isolation level
- Oracle 的 serializable isolation level
- SQL server 的 snapshot isolation level
(應該是類似樂觀鎖,使用快照隔離實作時就會有的 txid)
丟失更新檢測是一個很好的功能,因為它不需要應用程式碼使用任何特殊的資料庫功能,
你可能會忘記使用鎖或原子操作,從而引入錯誤;
但丟失更新的檢測是自動發生的,因此不太容易出錯。
比較和設置 CAS
- 根据数据库的实现情况,这可能也可能不安全
UPDATE wiki_pages
SET content = '新内容'
WHERE id = 1234 AND content = '旧内容';
在不提供交易的資料庫中,會發現這一種原子操作
但是,如果資料庫允許 WHERE 子句從舊快照中讀取,則此語句可能無法防止丟失更新,
因為即使發生了另一個並發寫入,WHERE 條件也可能為真。
在依賴資料庫的CAS操作前要檢查其是否安全。
衝突解決和複製
在支援複製的資料庫中(參見第5章),防止丟失的更新需要考慮另一個維度: 由於在多個節點上存在資料副本,並且在不同節點上的資料可能被並發地修改,因此需要採取一些額外的步驟來防止丟失更新。
鎖和CAS操作
鎖和CAS操作都假設最新的資料副本只有一個。
但是多主或無主複製的資料庫通常允許多個寫入並發執行,並以非同步的方式複製它們,因此無法保證資料的最新副本只有一個。
所以基於鎖或 CAS 操作的技術不適用於這種情況。(我們將在“可線性化”中更詳細地討論這個問題。)
正如“檢測並發寫入”一節所述 (P185),這種複製資料庫中的一種常見方法是允許並發寫入,
然後為一個值創建多個衝突版本(也稱為兄弟值 siblings),
並使用應用程式碼或特殊數據結構在事實發生之後解決和合併這些版本。
原子操作
原子操作可以在複製的情境中運作良好,尤其當它們具有可交換性時(即commutative,可以在不同的副本上以不同的順序執行時,且仍然可以得到相同的結果)。
例如,遞增計數器或向集合添加元素是可交換的操作。
(可交換性可能是講不同的操作之間沒有dependency,所以誰先做誰後做沒差)
這是Riak 2.0數據類型背後的思想,它可以防止複製副本丟失更新。
當不同的客戶端同時更新一個值時,Riak自動將更新合併在一起,以免丟失更新。
LWW
另一方面,最後寫入為準(LWW)的衝突解決方法很容易丟失更新,如“最後寫入為準(丟棄並發寫入)”中所述。
不幸的是,LWW是許多複製資料庫中的默認值。
寫入偏斜(偏差)和幻讀 write skew and phantom
並發寫入間可能發生的競爭條件還沒有完。在本節中,我們將看到一些更微妙的衝突例子。
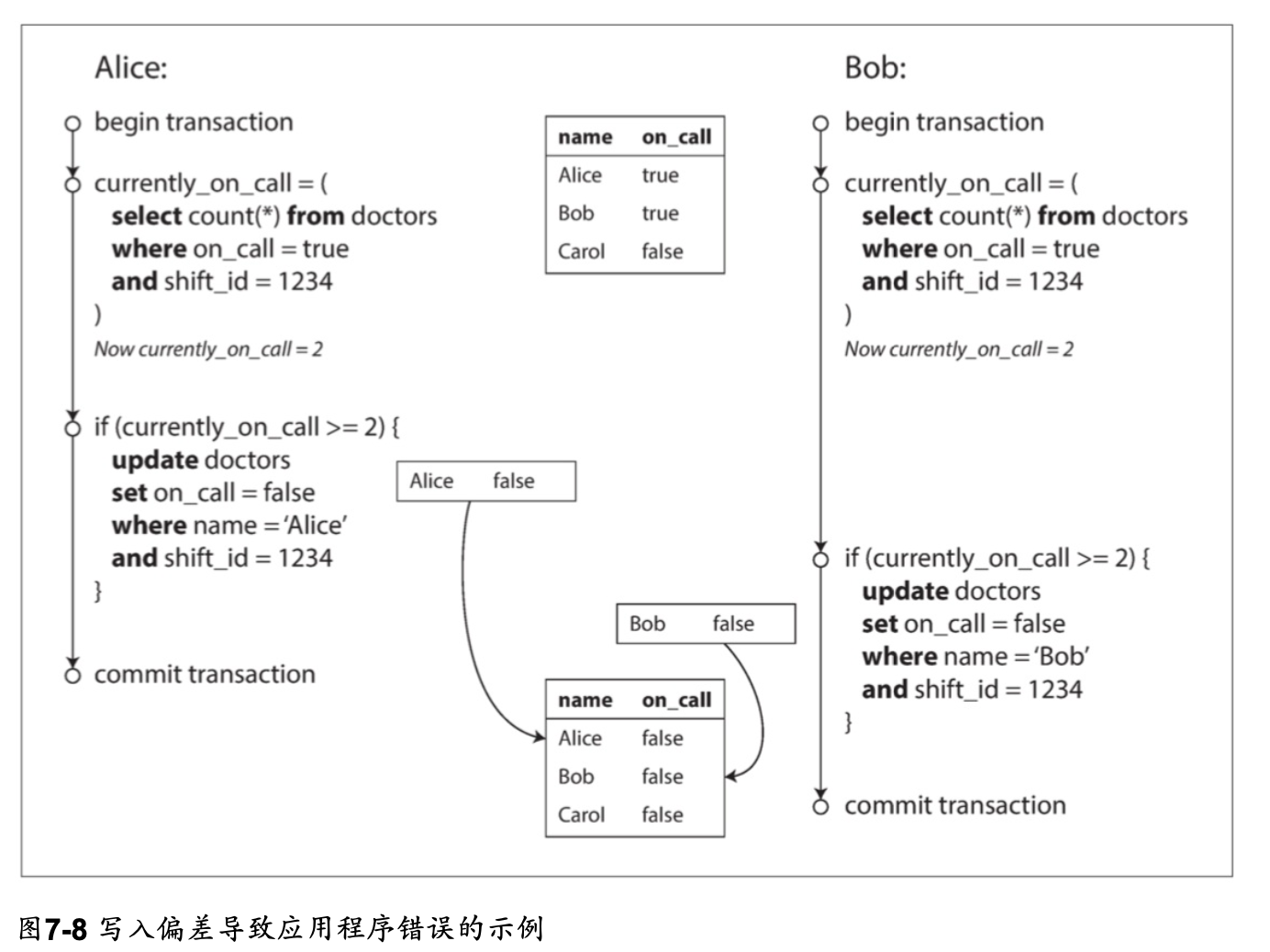
寫入偏斜(偏差)的特徵
這種異常稱為寫入偏差(寫入的結果歪掉了)。 它既不是髒寫,也不是丟失更新,因為這兩個交易正在更新兩個不同的對象(Alice和Bob各自的待命記錄)。
在這裡發生的衝突並不是那麼明顯,但是這顯然是一種競爭條件: 如果兩個交易一個接一個地運行,那麼第二個醫生就不能歇班了。異常行為只有在交易並發進行時才有可能。
可以將寫入偏差看作是更廣義的 lost update
我們看到,有各種不同的方法來防止丟失的更新。對於寫入偏差,我們的選擇更受限制:
- 由於涉及多個物件,單物件的原子操作不起作用。
- 在 PostgreSQL的可重複讀,MySQL/InnoDB的可重複讀,Oracle可序列化或SQL Server的快照隔離級別中,都不會自動檢測寫入偏差。
- 自動防止寫入偏差需要真正的可序列化隔離(請參見“可序列化”)。
- 某些資料庫允許配置約束,然後由資料庫強制執行(例如,唯一性,外鍵約束或特定值限制)。但是為了指定至少有一名醫生必須線上,需要一個涉及多個物件的約束。大多數資料庫沒有內置對這種約束的支持,但是你可以使用 Trigger,或者 Materialze View 來實作,這取決於不同的資料庫。
- 如果無法使用可序列化的隔離級別,則此情況下的次優選項可能是顯式鎖定交易所依賴 的行。在例子中,你可以寫下如下的程式碼:
BEGIN TRANSACTION;
SELECT *
FROM doctors
WHERE on_call = TRUE
AND shift_id = 1234
FOR UPDATE;
UPDATE doctors
SET on_call = FALSE
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;
更多寫入偏斜(差)的例子
會議室預約系統
BEGIN TRANSACTION;
-- 检查所有现存的与12:00~13:00重叠的预定
SELECT COUNT(*)
FROM bookings
WHERE room_id = 123
AND end_time > '2015-01-01 12:00'
AND start_time < '2015-01-01 13:00';
-- 如果之前的查询返回0
INSERT INTO bookings (room_id, start_time, end_time, user_id)
VALUES (123, '2015-01-01 12:00', '2015-01-01 13:00', 666);
COMMIT;
快照隔離並不能防止另一個使用者同時插入衝突的會議。為了確保不會遇到調度衝突,你又需要可序列化的隔離級別了。
多人線上遊戲
在範例7-1中,我們使用一個鎖來防止丟失更新(也就是確保兩個玩家不能同時移動同一個棋子)。
但是鎖定並不妨礙玩家將兩個不同的棋子移動到棋盤上的相同位置,或者採取其他違反遊戲規則的行為。
按照您正在執行的規則類型,也許可以使用唯一約束,否則您很容易發生寫入偏差。
申請新帳號
在每個使用者擁有唯一使用者名的網站上,兩個使用者可能會嘗試同時建立具有相同使用者名的帳戶。
可以在交易檢查名稱是否被搶佔,如果沒有則使用該名稱建立帳戶。
但是像在前面的例子中那樣,在快照隔離下這是不安全的。
幸運的是,唯一約束是一個簡單的解決辦法(第二個交易在提交時會因為違反使用者名稱唯一約束而被中止)。
防止過度消費
允許使用者花錢或積分的服務,需要檢查使用者的支付金額不超過其餘額。
可以通過在使用者的帳戶中插入一個臨時的支出項目來實作,列出帳戶中的所有項目,並檢查總和是否為正值。
但併發導致可能會發生兩個支出項目同時插入,一起導致餘額變為負值,但這兩個交易都不會注意到另一個,造成寫入偏差。
造成寫入偏斜(差)的幻讀
上述寫入偏斜(差)的例子,都遵循類似的模式,
一個交易中的寫入改變另一個交易的查詢的結果,被稱為幻讀。
(像幻影般的資料,曾經在我面前,卻又消失不見)
快照隔離避免了 readonly 查詢中的幻讀 (指的是可以 repeatable read 了,repeatable read 就是要防止幻讀造成的 read skew), 但是在像我們討論的例子那樣的讀寫交易中,幻讀會導致特別棘手的寫入偏斜情況。
(簡單來說,應用程式如果會依賴讀取的結果決定某些功能運作是否成立或者是否有意義,就要注意在併發的狀況下是否有可能會有race condition導致的偏斜結果)
實體化衝突 materializing conflicts
如果幻讀的問題是沒有物件可以加鎖,也許可以人為地在資料庫中引入一個鎖物件?
把有可能遇到幻讀的資料,變成一條具體的 db record,然後就可以對這個 record 上鎖 (SELECT FOR UPDATE) 去 block 另外一個併發的交易
這種方法被稱為物化衝突(materializing conflicts),因為它將幻讀變為資料庫中一組具體行上的鎖衝突
不幸的是,弄清楚如何物化衝突可能很難,也很容易出錯,而讓並發控制機制影響到應用資料模型是很醜陋的做法。
出於這些原因,如果沒有其他辦法可以實現,物化衝突應被視為最後的手段。
在大多數情況下。可序列化(Serializable) 的隔離級別是更可取的。
Take Away
- 明白應用程式對於db的操作會在各種層面遭遇故障 (所以原子性很重要)
- 知道資料庫隔離保證有不同等級
- 善用原子自增SQL語法,避免 lost update
- 對於Phantom幻讀造成的應用程式功能異常有awareness
- race conditon, race conditon and race conditon
- 知道分散式資料庫對於交易的ACID保證會有所犧牲
可序列化
可序列化(Serializability)隔離通常被認為是最強的隔離級別。它保證即使事務可以並行執 行,最終的結果也是一樣的,就好像它們沒有任何並發性,連續挨個執行一樣。
真的串行執行
一次在一個綫程上只執行一個事務。
之所以現在可以單綫程執行,是因為:
- RAM足夠便宜
- OTLP事務通常很短,只有少數讀寫。
且長時間運行的分析查詢通常是只讀,可以從快照讀取(在串行之外執行)
在存儲過程中封裝事務
實際應用場景中,有些事務以交互式的客戶端-服務器的風格執行,且一個事務有多個查詢語句,查詢和結果在應用程序和數據庫之間來回傳遞。
在這種場景中,大量時間花費在網路通信上,數據庫通常在等應用程序發出當前事務的下一個請求。 如果我們將含多個查詢的整個事務封裝在一個存儲過程中,提交給數據庫,就可以減少網路通信的開銷。
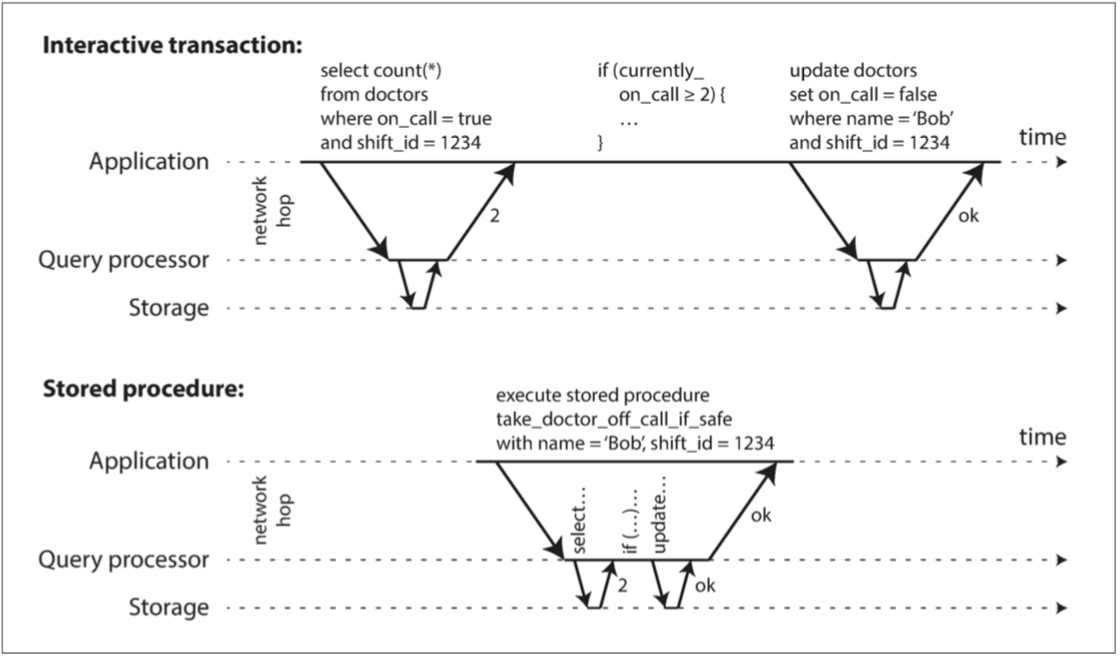 Figure 7-9
Figure 7-9
存儲過程的優缺點
優點: 不需要等待I/O,且避免了并發控制機制的開銷,可以有很好的吞吐量。
缺點:
- 很難寫
各個數據庫都有自己的存儲過程的語言(Oracle有PL/SQL,SQL Server有T-SQL, PostgreSQL有PL/pgSQL等),沒有太跟上通用編程語言的發展。 - 管理困難
不好debug,不好版控,不好部署,不好加tracing監控 - 寫不好有風險
數據庫通常被多個應用程序共享,一個存儲過程的性能問題可能影響到其他應用程序。
不過,現代的存儲過程已經有了很多改進,放棄了PL/pgSQL,有使用通用的編程語言: VoltDB使用Java或Groovy,Datomic使用Java或Clojure,而Redis使用Lua。
分區
順序執行的數據庫性能受限於單機單核的速度,可以通過分區來提高性能。
有兩種情況:
- 單分區事務
如果可以找到一種對數據集的分區方式,使得每個事務只需要訪問一個分區,那麼就可以並行執行多個事務,事務吞吐量就可以與CPU核數保持綫性擴展。 - 多分區事務
如果事務需要訪問多個分區,那存儲過程需要做好協調,跨越分區鎖定執行,以確保系統的可串行性,比單分區慢得多。
例如: VoltDB支援1000個跨分區寫入/s,比單分區吞吐量低幾個數量級,且不能通過增加機器來提高吞吐量。
事務能否劃分為單分區事務取決於數據結構:
簡單的Key-Value存儲,可以很容易劃分為單分區事務。
但是有多個二級索引的數據就不行,需要跨分區(見ch6)。
两相锁定(2PL, two-phase locking)
目前保證可串行性的主流方法,因包含獲取鎖和釋放鎖兩個階段而得名。
2PL為每個數據庫對象添加鎖, 鎖可以處於共享模式(shared mode,共享鎖)或獨占模式(exclusive mode,排他鎖),使用方式如下:
- 共享鎖:讀取數據時使用,允許多個事務同時有共享鎖。 但如果有任一事務在該對象上有排他鎖,所有其他事務都必須等待
- 事務要寫入必須有排他鎖,如果對象上有任何鎖,該事務都必須等待。
- 事務獲得鎖之後必須持有鎖直到事務結束
數據庫自動檢測事務之間的死鎖並終止其中一個。
性能
2PL事務吞吐量與查詢響應時間要比弱隔離級別的差得多,因為:
- 鎖的開銷
- 并發性的降低 如果兩個并發事務試圖做可能導致競爭條件的事情,則其中一個事務必須等待另一個事務完成。
一個緩慢的事務,或一個訪問大量數據并獲取許多鎖的事務,就會把系統的其他部分拖慢或迫使系統停機, 增加了系統的不穩定性。
且如果常有死鎖,事務就常會被終止並重試,很浪費資源。
謂詞鎖
是一種特殊的鎖,也有兩種模式,但它不屬於一個對象而屬於所有符合搜索條件的對象,用於防止幻影。
謂詞鎖限制訪問如下:
- 如果事務A想要讀取匹配某些條件的對象,它必須獲取 查詢條件上的共享謂詞鎖(shared-mode predicate lock)。如果另一個事務B持有任何 滿足這一查詢條件對象的排他鎖,那麼A必須等到B釋放它的鎖之後才允許進行查詢。
- 如果事務A想要插入,更新或刪除任何對象,則必須首先檢查舊值或新值是否與任何現有 的謂詞鎖匹配。如果事務B持有匹配的謂詞鎖,那麼A必須等到B已經提交或中止後才能 繼續。
如果兩階段鎖定包含謂詞鎖,則資料庫將阻止所有形式的寫入偏差和其他競爭條件, 因此其隔離實現了可串行化。
索引範圍鎖
因爲謂詞鎖性能不佳:如果活躍事務持有很多鎖,檢查匹配的鎖會非常耗時。 因此,大多數使用2PL的資料庫實際上實現了索引範圍鎖(也稱為間隙鎖(next-key locking)),這 是一個簡化的近似版謂詞鎖。
對於索引而不是具體的查詢條件上鎖,比謂詞鎖更寬汎地鎖定對象,可以在開銷較低的情況下防止幻影。
例如,要預定12-13點的房間123,資料庫可能會在 room_id 列上有一個索引,並且/或者在 start_time 和 end_time 上有索引(否則前面的查詢在大型資料庫上的速度會非常慢):
- 假設索引位於 room_id 上,並且資料庫使用此索引查找123號房間的現有預訂。現在 資料庫可以簡單地將共享鎖附加到這個索引項上,指示事務已搜尋123號房間用於預訂。
- 或者,如果資料庫使用基於時間的索引來查找現有預訂,那麼它可以將共享鎖附加到該 索引中的一系列值,指示事務已經將12:00~13:00時間段標記為用於預定。
無論哪種方式,搜尋條件的近似值都附加到其中一個索引上。現在,如果另一個事務想要插 入,更新或刪除同一個房間和/或重疊時間段的預訂,則它將不得不更新索引的相同部分。在 這樣做的過程中,它會遇到共享鎖,它將被迫等到鎖被釋放。
這種方法能夠有效防止幻讀和寫入偏差。索引範圍鎖並不像謂詞鎖那樣精確(它們可能會鎖 定更大範圍的對象,而不是維持可串行化所必需的範圍),但是由於它們的開銷較低,所以 是一個很好的折衷。
可序列化的快照隔离(serializable snapshot isolation)
悲觀與樂觀的并發控制
悲觀(pessimistic):任何事情都可能出錯,所以最好等到情況安全再做事。 2PL、真的串行執行都屬於悲觀的并發控制。
樂觀(optimistic):假設一切都會順利,直到出錯才回滾。 SSI是樂觀的并發控制。
如果有足夠的備用容量,並且事務之間的爭用(contention)(很多事務試圖訪問相同的對象)不是太高,樂觀并發的性能比悲觀的要好。 但如果有很多爭用,樂觀并發的性能會變差,因為很多事務會被迫回滾重試。
基於快照隔離的可串行化,事務中的所有讀取都是來自資料庫的一致性快照(見ch6快照隔離)。 在快照隔離的基礎上,SSI添加了一種算法來檢測寫入之間的序列化衝突,並確定要中止哪些事務。
解決基于过时前提的决策
之前快照隔離提到的寫入偏差的根本原因是事務的寫操作是基於一個過時了的快照(前提premise)。 數據庫要能夠知道查詢結果可能已經改變:
- 檢測對舊MVCC對象版本的讀取(讀之前存在未提交的寫入)
- 檢測影響先前讀取的寫入(讀之後發生寫入)
检测旧MVCC读取
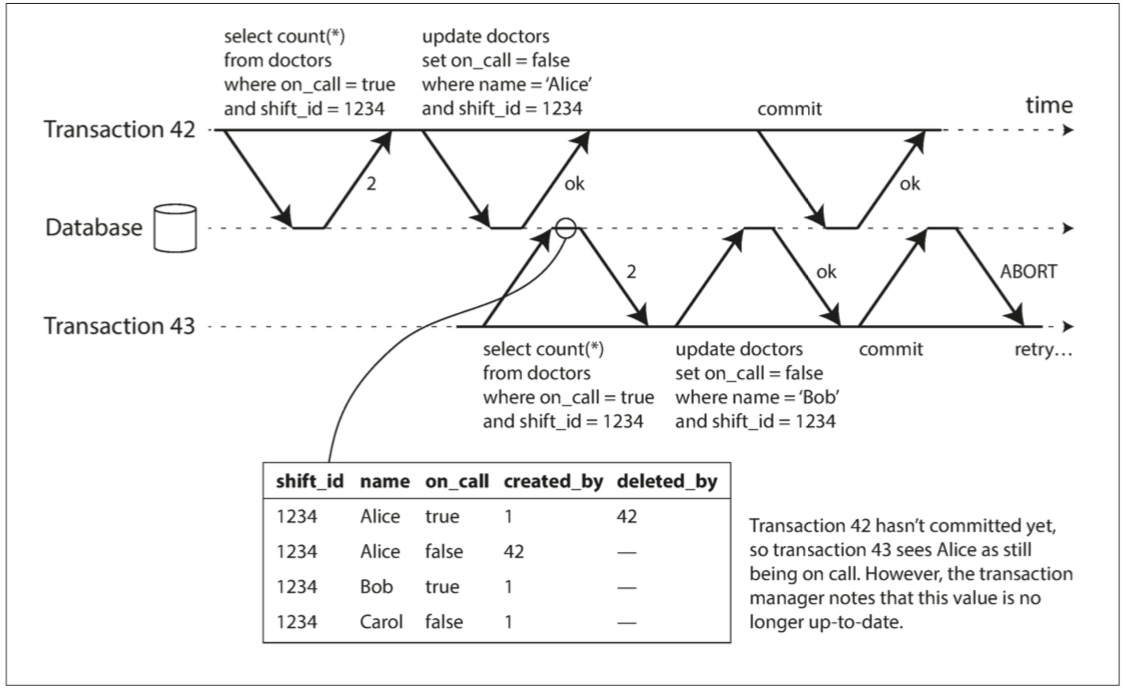 Figure 7-10
Figure 7-10
爲了檢測對舊MVCC對象版本的讀取,SSI需要在事務開始時記錄事務開始時的快照。 當事務想要提交時,資料庫檢查是否有任何被忽略的寫入現在已經被提交。 如果是這樣,事務必須中止。
等到事務提交時再檢查的好處是,對於只讀事務不需要終止,因爲沒有寫入偏差的風險。 而且,快照可能不是舊的,可以避免不必要的中止。e.g. 事務42可能還是晚於事務43提交。
检测影响之前读取的写入
使用類似於索引範圍鎖的技術,加SSI索引,僅起到通知作用,而不阻塞其他事務。 當事務寫入資料庫時,它必須在SSI索引中查找最近曾讀取受影響資料的其他事務,如果有衝突寫入就中止。
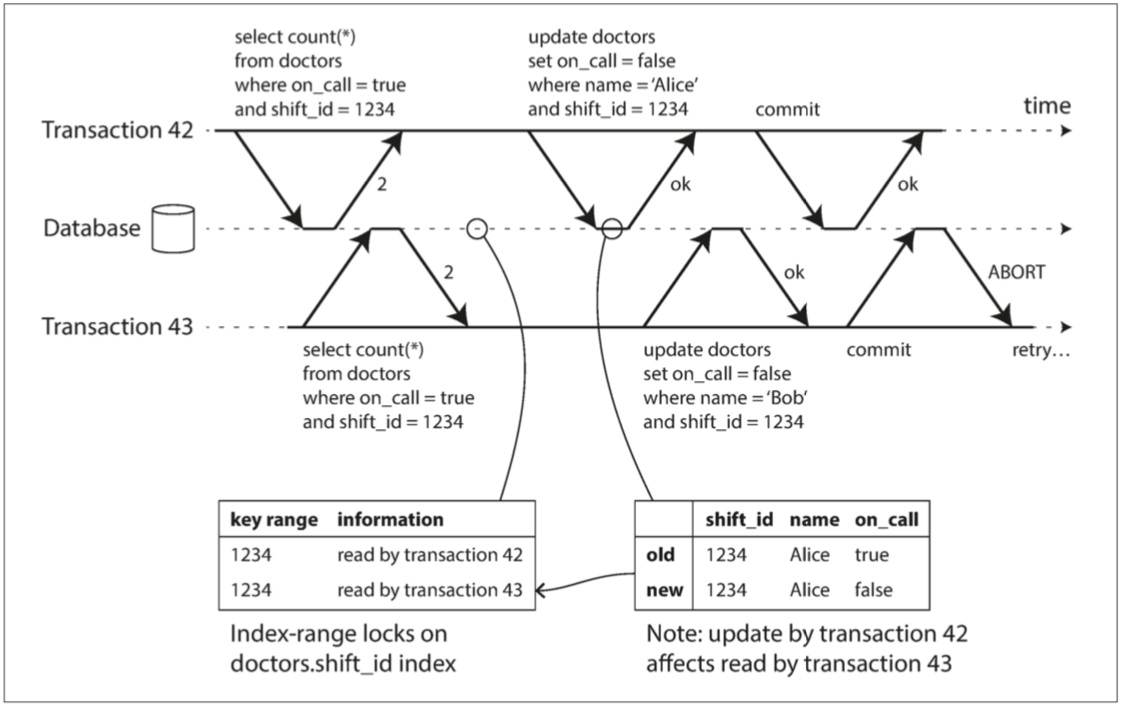 Figure 7-11
Figure 7-11
SSI的性能在可序列化方式中最優
| 與其他可序列化方式相比 | SSI的優勢 |
|---|---|
| 2PL | 一個事務不需要阻塞等待另一個事務所持有的鎖,在讀取繁重的應用中表現會很好 |
| 串行執行 | 不局限於單個CPU核的吞吐量 |
不過,中止率顯著影響SSI的整體表現。例如,長時間讀取和寫入資料的事務很可能會發生衝突並中止,因此SSI要求同時讀寫的事務儘量短(只讀長事務可能沒問題)。
但是的但是,對於慢事務,SSI也比兩階段鎖定或串行執行更不敏感。
GPT告訴我,實現可序列化快照隔離(SSI, Serializable Snapshot Isolation)的數據庫包括以下幾個:
PostgreSQL:自9.1版本起,PostgreSQL支持SSI作為一個可選的事務隔離等級。這是一個廣泛使用的開源關係型數據庫,支持許多應用程序的開發。
FoundationDB:FoundationDB是一個分布式鍵值存儲系統,專為高性能和高可靠性而設計。它提供了一個強大的事務模型,支持可序列化快照隔離。蘋果公司於2015年收購了FoundationDB,並在2018年以開源形式重新發布。
VoltDB:VoltDB是一個開源的新型關係型數據庫,提供高性能、高吞吐量的事務處理。它支持可序列化快照隔離,並且專為垂直分區和分布式計算而設計。
CockroachDB:CockroachDB是一個開源的分布式SQL數據庫,旨在實現全球數據存儲和無縫擴展。CockroachDB支持可序列化快照隔離,確保事務的一致性和隔離性。
總結
本章通過幾個競爭條件深入討論幾個廣汎使用的隔離級別:
| 競爭條件 | 描述 | 解決方案 |
|---|---|---|
| 脏读 | 客戶端讀取到另一客戶端尚未提交的寫入 | 讀已提交或更強的隔離級別 |
| 脏寫 | 客戶端覆蓋寫入了另一客戶端尚未提交的寫入 | 幾乎所有的事務實現 |
| 不可重複讀 | 客戶端在同一事務中看見數據庫的不同狀態 | 快照隔離(MVCC實現) |
| 更新丟失 | 讀取-修改-寫入序列的衝突,數據丟失 | 快照隔離或手動鎖定(SELECT FOR UPDATE) |
| 寫偏差 | 事務寫入時,所依據的前提不再成立 | 只有可序列化的隔離級別 |
| 幻讀 | 搜尋結果受到另一客戶端寫入的影響 | 快照隔離或特殊處理(例如索引範圍鎖定) |
可序列化是最强的隔離級別,實現可序列化事務的三種方法:
- 字面意義上的串行執行:適用於單CPU核上的低事務吞吐量場景。
- 兩階段鎖定:實現可序列化的標準方式,但可能遇到性能問題。
- 可串行化快照隔離(SSI):新的算法,避免先前方法的大部分缺點,使用樂觀方法,允許事務執行而無需阻塞。